I often get asked is there a way to download Databricks’s cell execution results to local ? The answer as you guessed correctly is you can. The most common way is to use the Download as CSV button in the Notebook UI (as shown below). You can choose between retrieving full result set or partial results for quick preview. There is also a less known yet powerful approach called Command API. You can use it to send PySpark, R or Scala code from your local IDE to a Databricks cluster and retrieve the execution results locally. I even wrote a Python utility to help facilitate this process which I will share in this post.
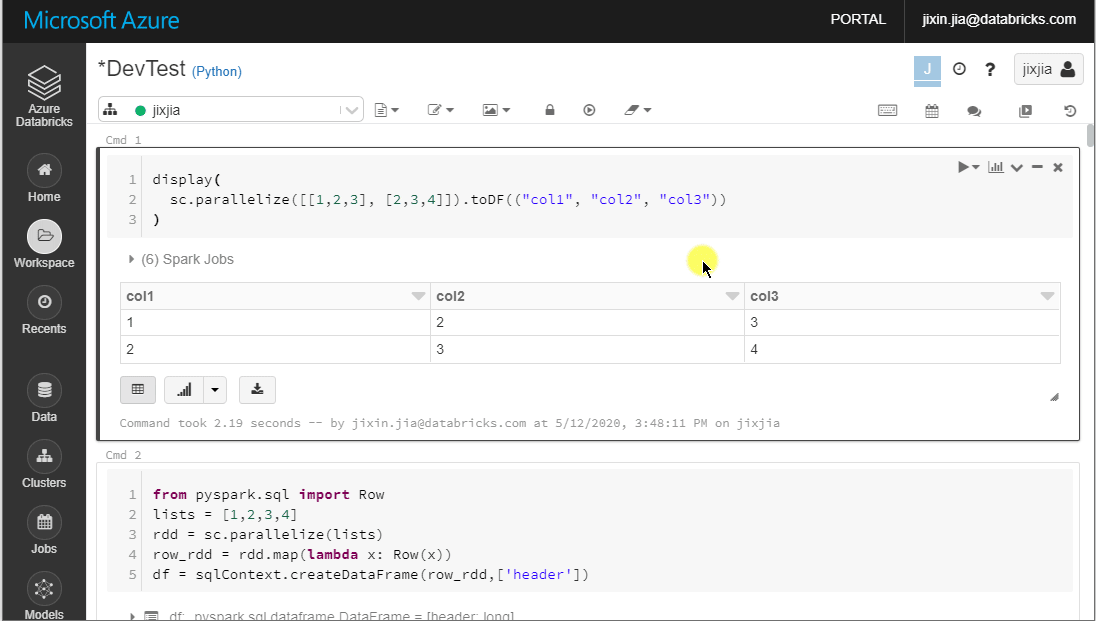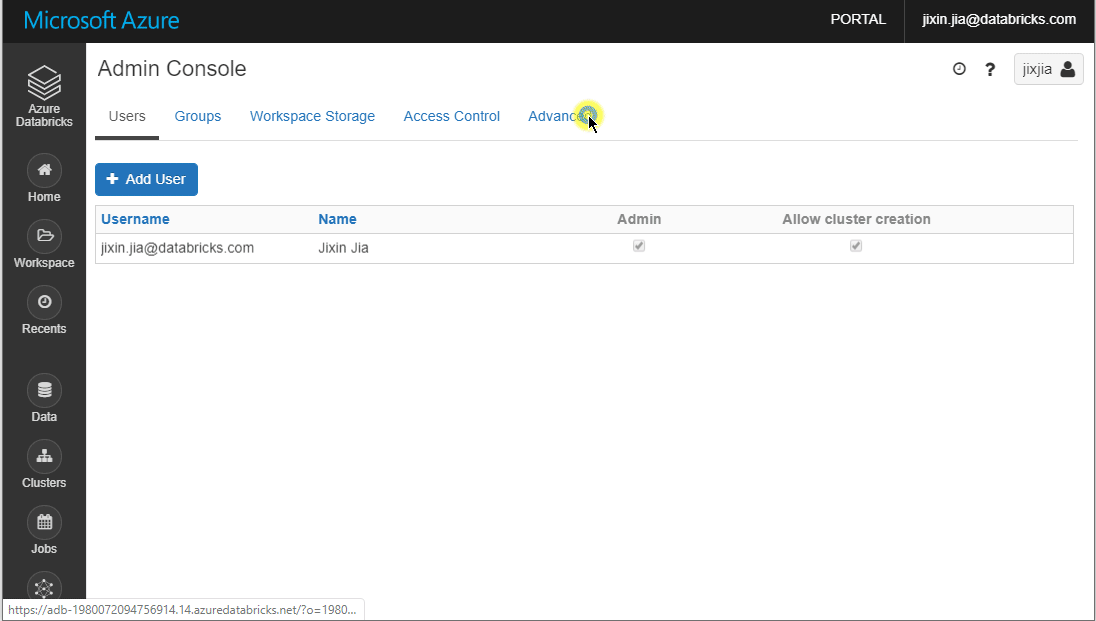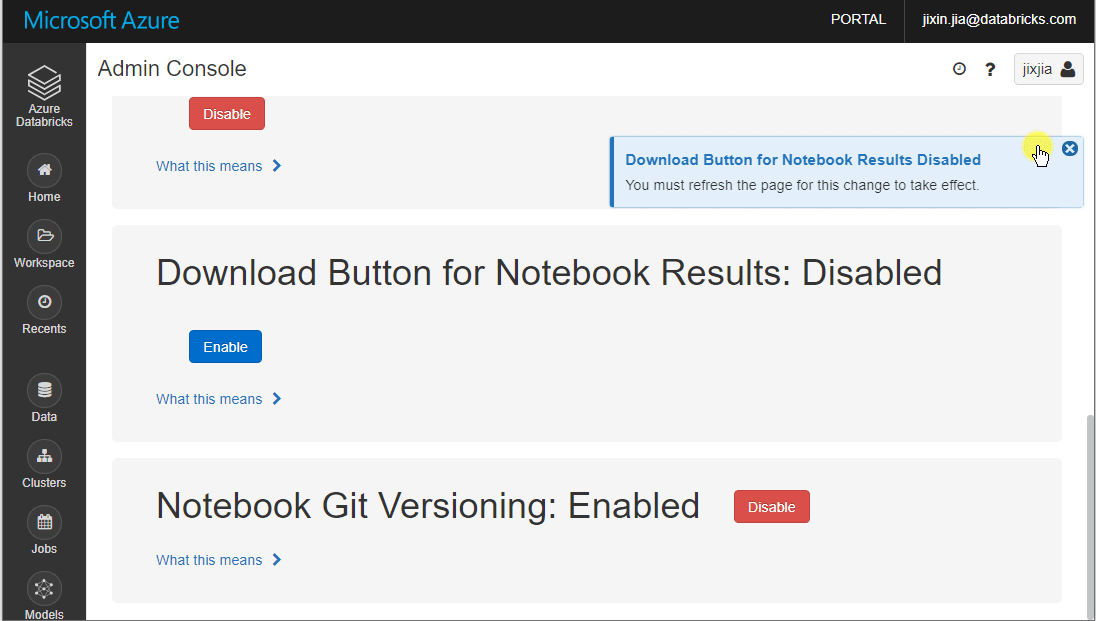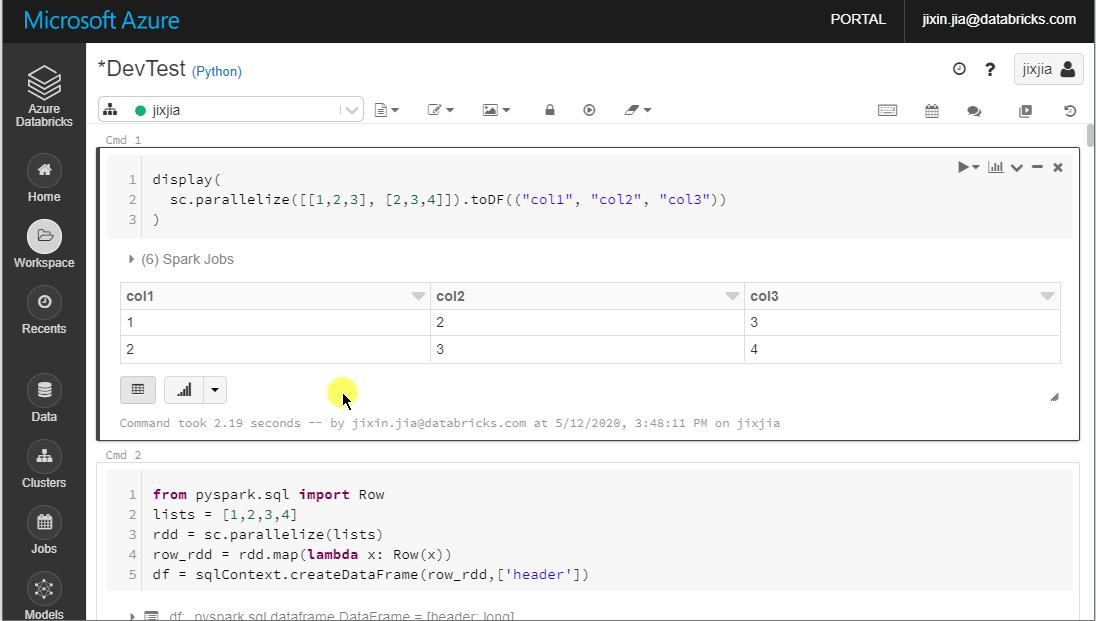
Method 1 – Download as CSV
The Notebook UI already provides a convenient way to download the entire or partial (up to 1000 rows) ouputs from a cell that contains Data frame.
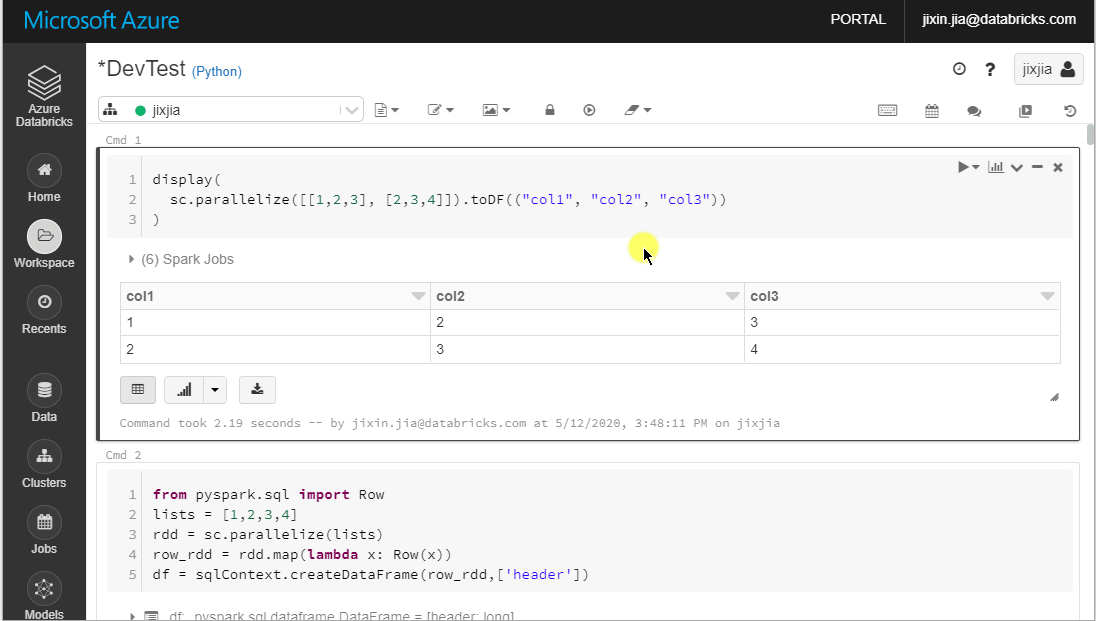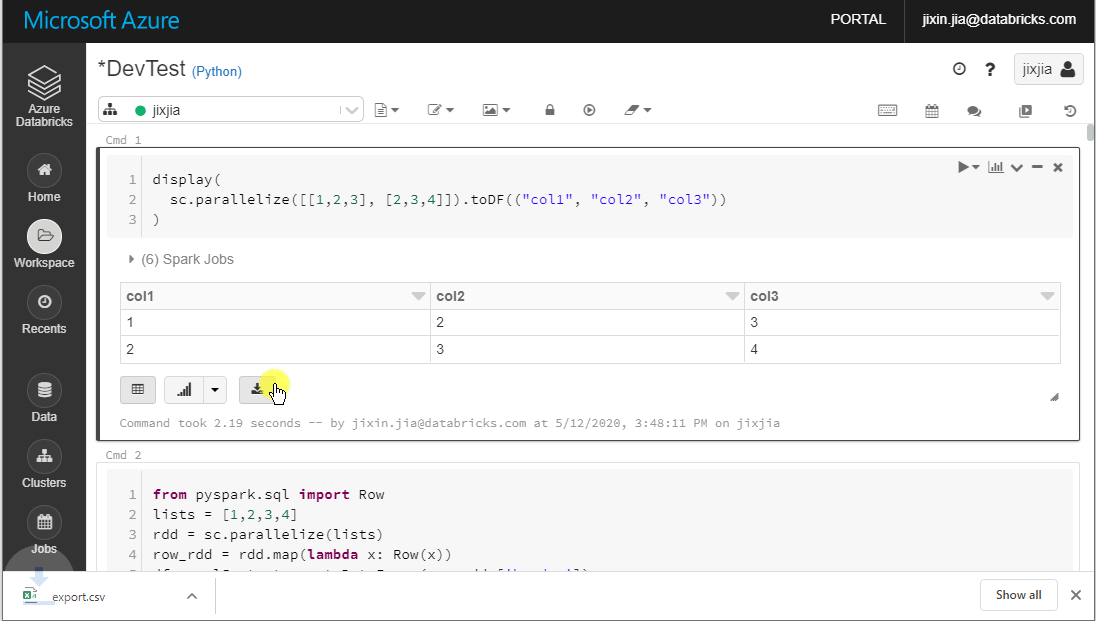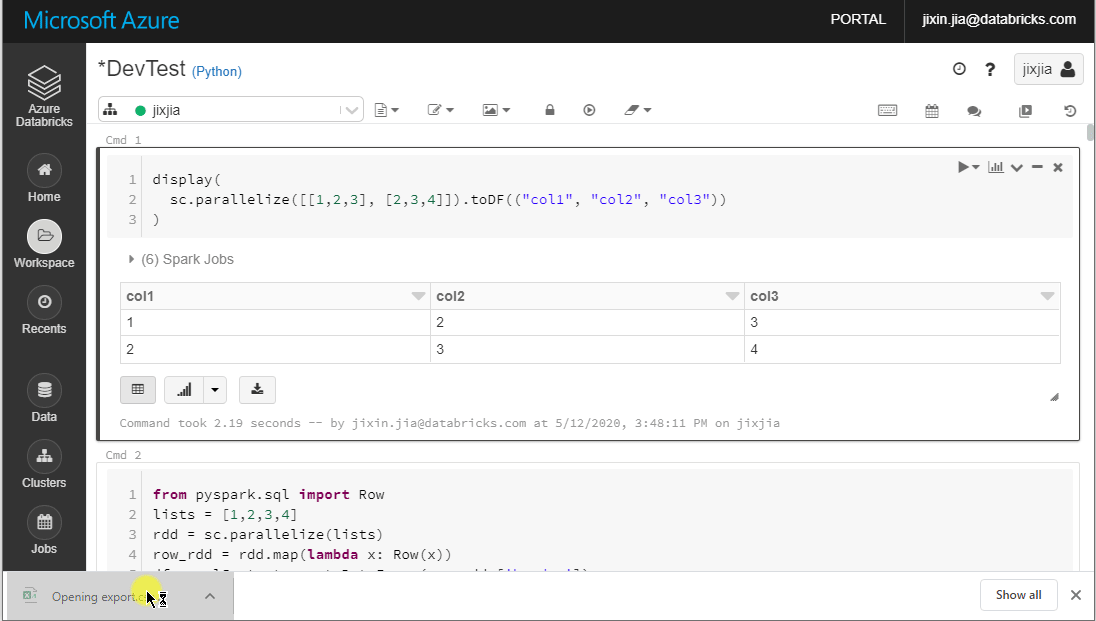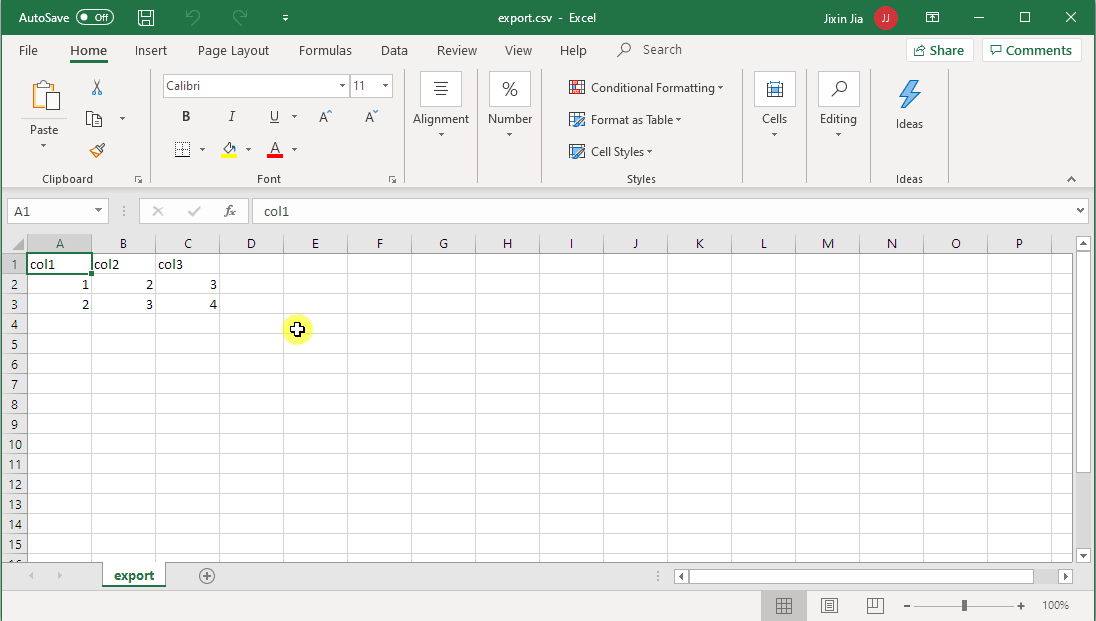
In case you wish to prevent users from exporting the results, you can disable this function from Admin Console > Advanced and set Download Button for Notebook Results to Disabled:
Method 2 – Using Command API
I wrote a Python utility to help streamlining the use of Command API. This utility lets you easily submit your own Spark query and get results back to local.
Download Utility
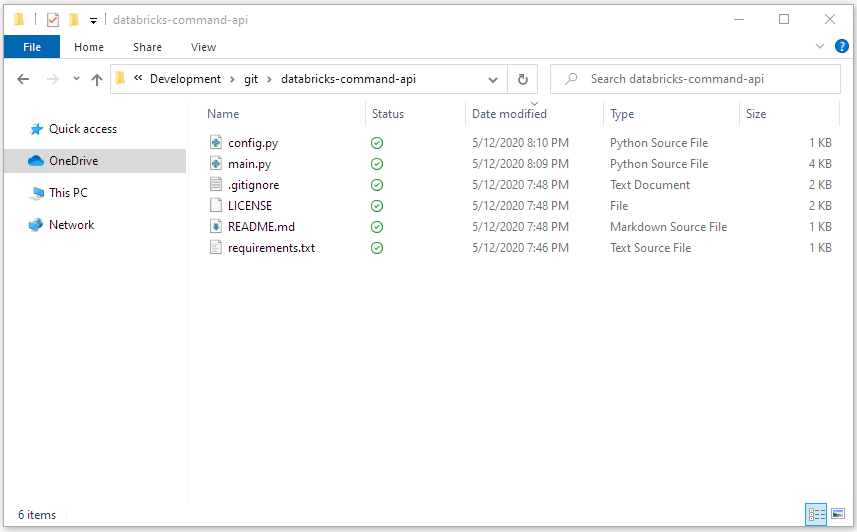
Clone or download the utility from my git repo:
git clone https://github.com/jixjia/databricks-command-api.gitYou should see following files downloaded:
Execute Query
To submit your own query simply run:
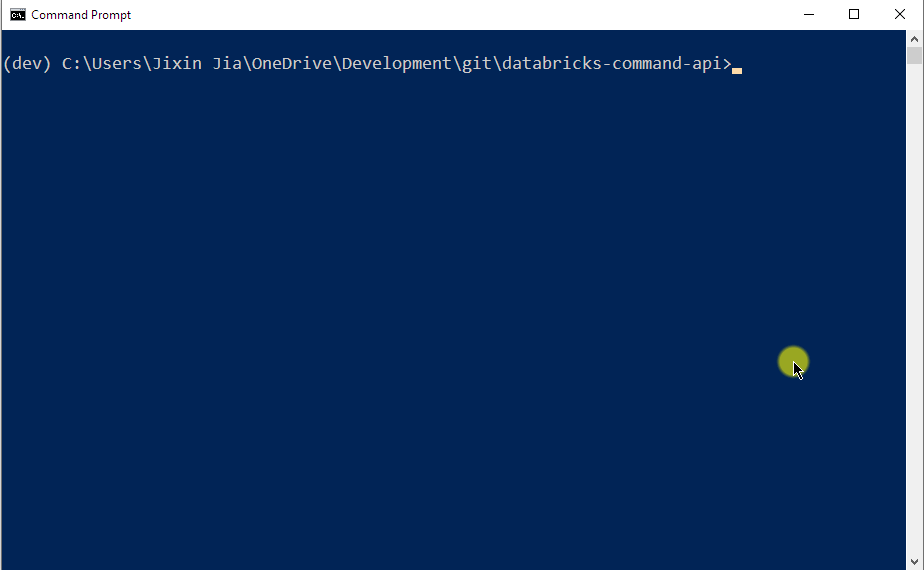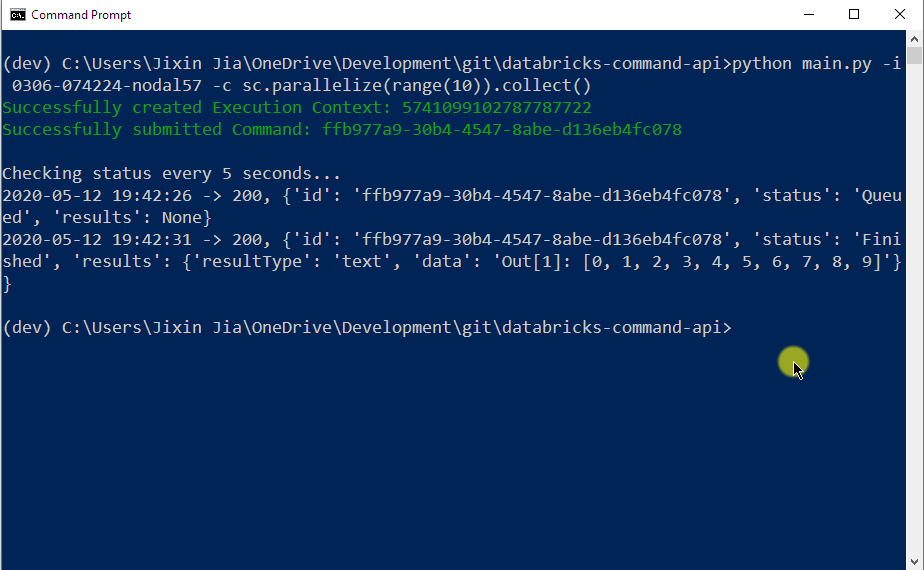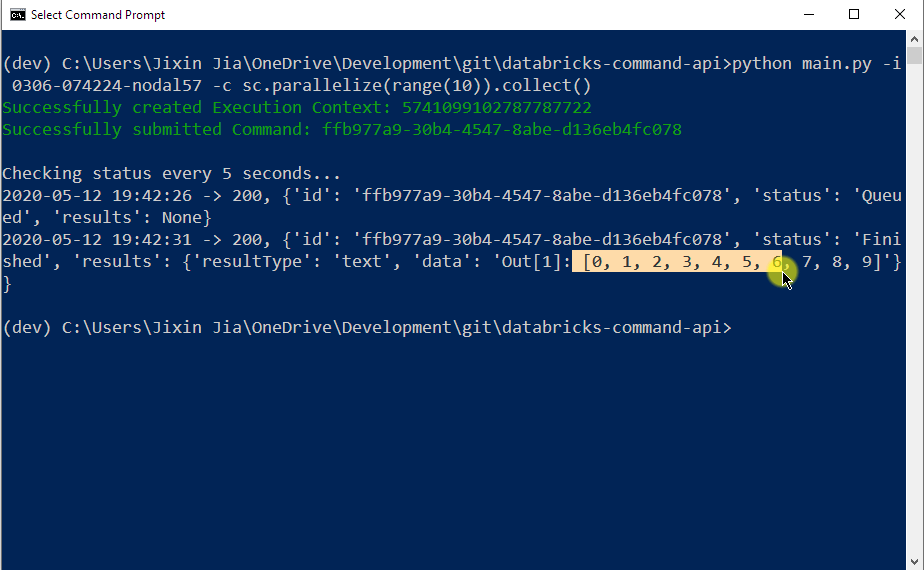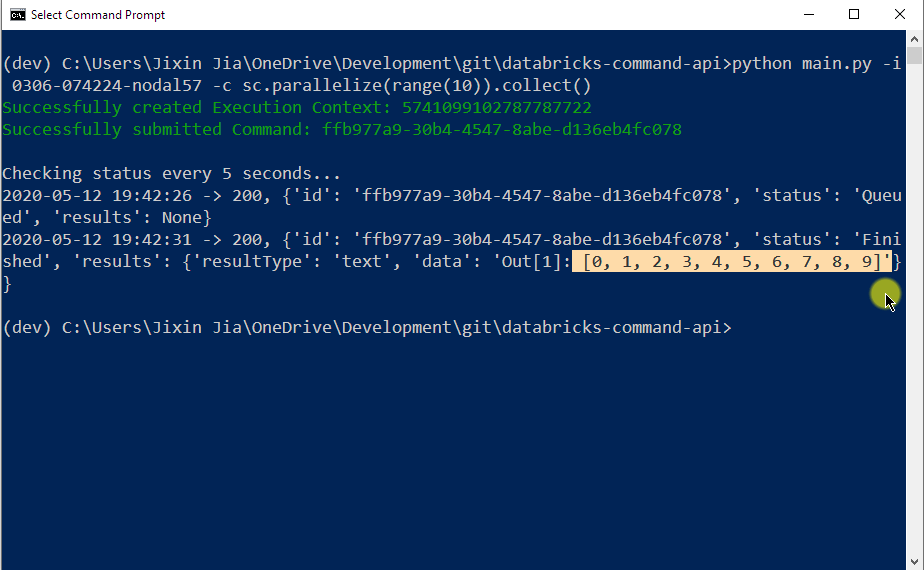
python main.py -i {DATABRICKS_CLUSTER_ID} -c {YOUR_SPARK_QUERY}In the following example I submitted a PySpark query that produces a list of numbers ranging from 0 to 9. Notice that the query was initiated from my Command Prompt. The execution output was pulled back from Databricks cluster in JSON format as highlighted in the screenshot:
Databricks Cluster ID
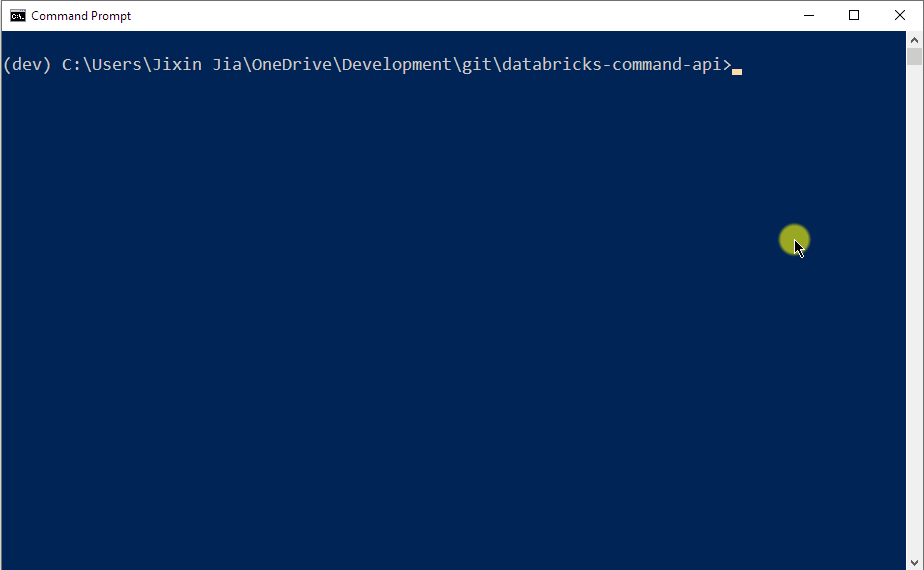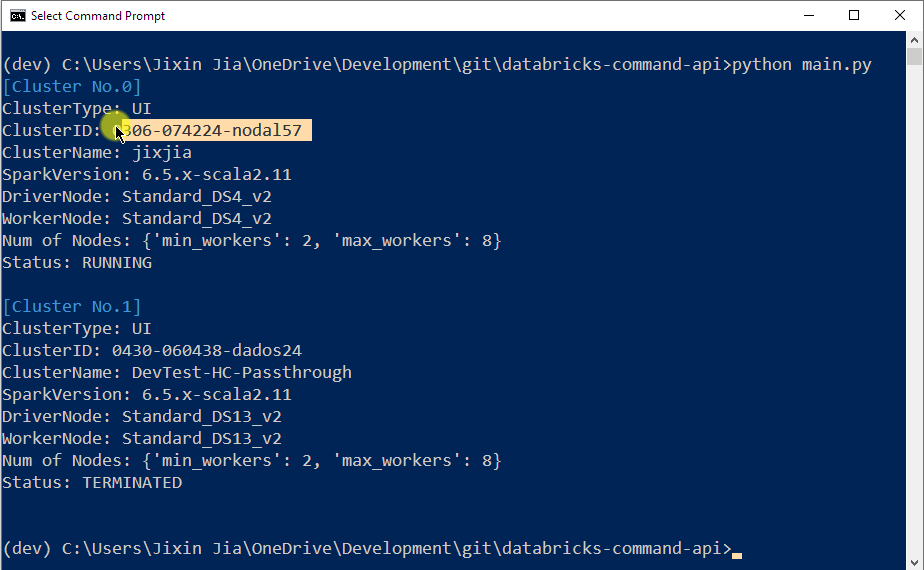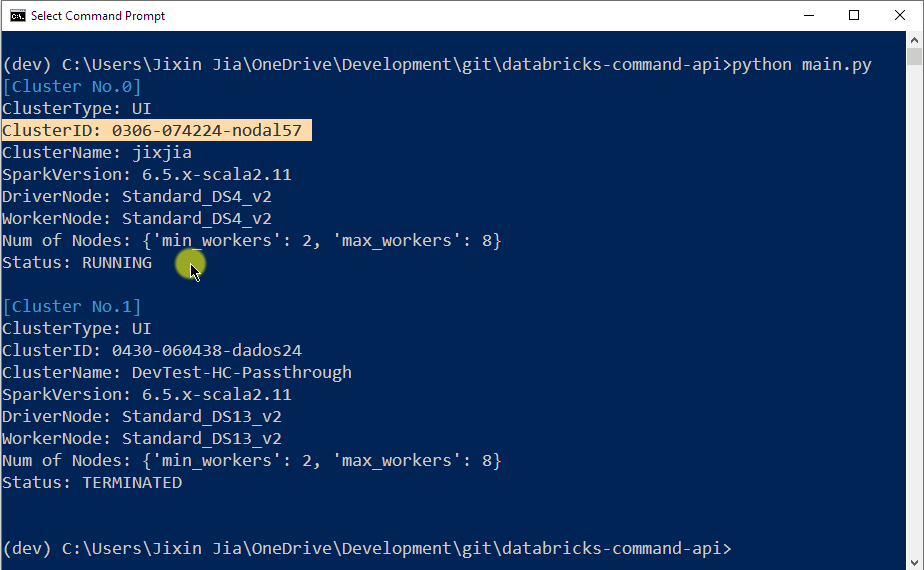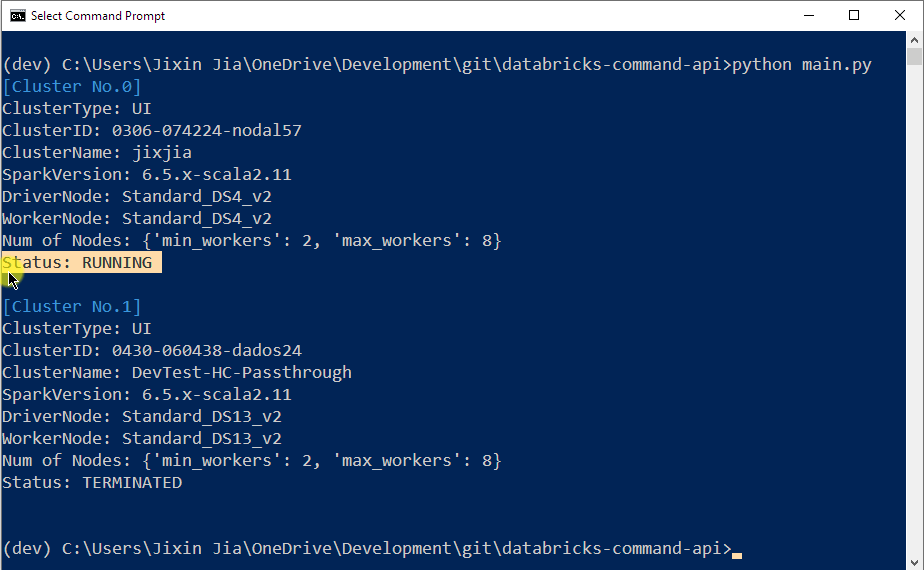
To specify which Databricks cluster to use, you need to tell the utility the Cluster Id. You can get this simply by running python main.py without adding any argument, and this utility will list all your existing Interactive Cluster’s information for you. Pick the one you want to use and check their status shows RUNNING:
Databricks URL and Token
In order to authenticate to the Databricks gateway (to show that you have permission to throw query against the cluster), you must supply your Databricks URL and Personal Access Token to the config.py file as following:
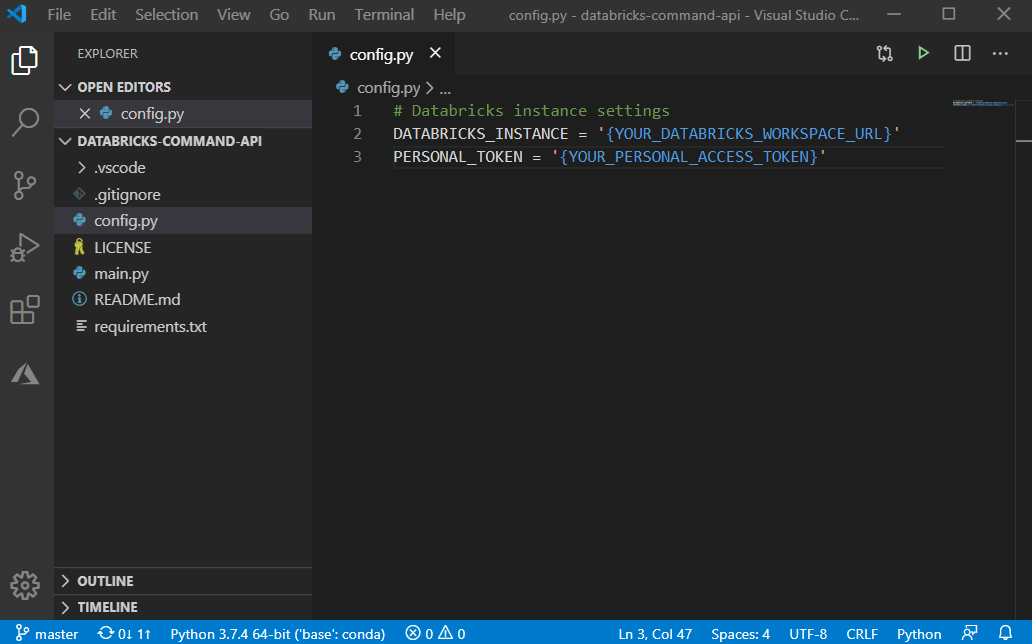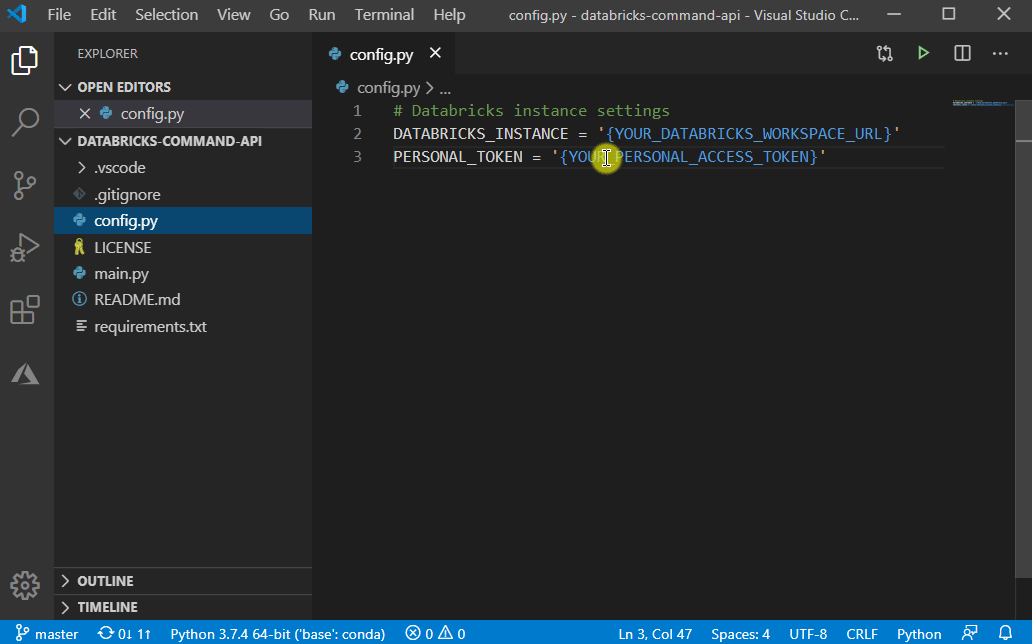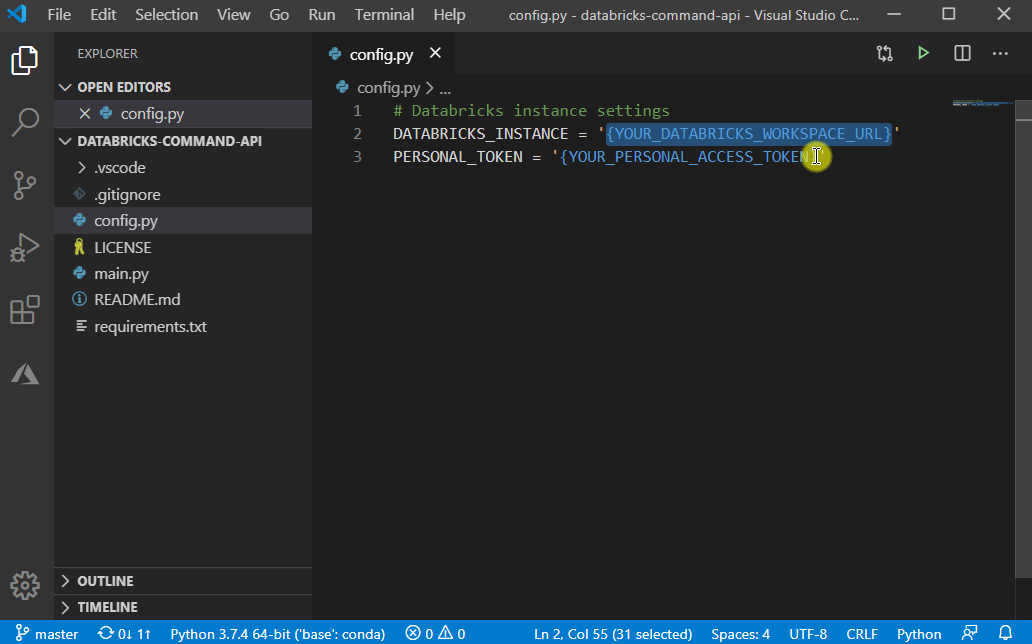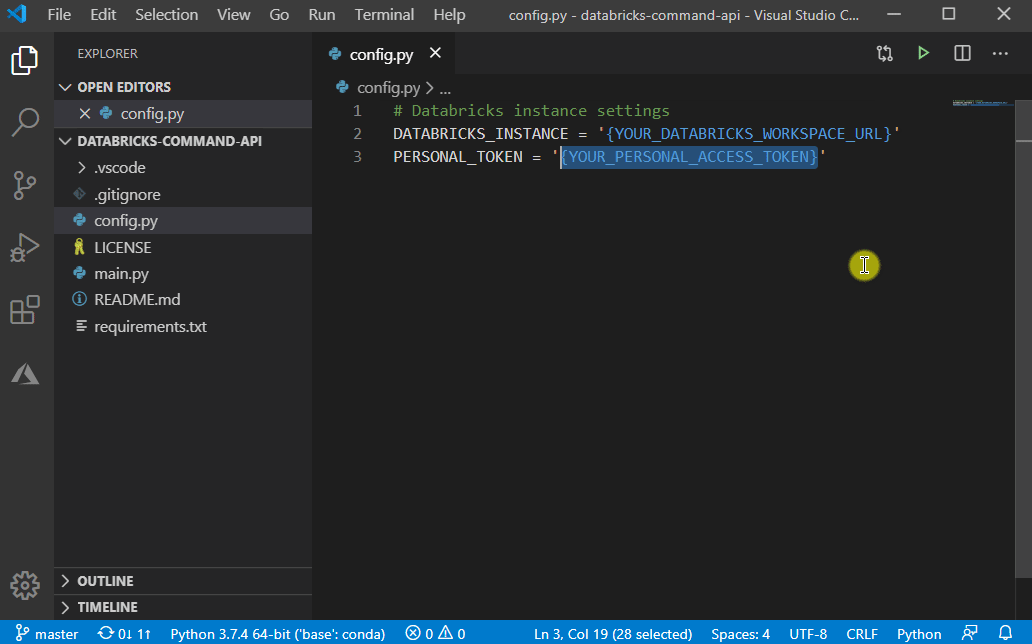
(1) Databricks URL
To get your Databricks’s workspace URL simply navigate to your workspace domain in the browser. For Azure this should look like below (as of 2020 May 13):
adb-<WORKSPACE_ID>.<RANDOM_NUMBER>.azuredatabricks.net
For AWS the URL has following format:
<YOUR_ACCOUNT>.cloud.databricks.com
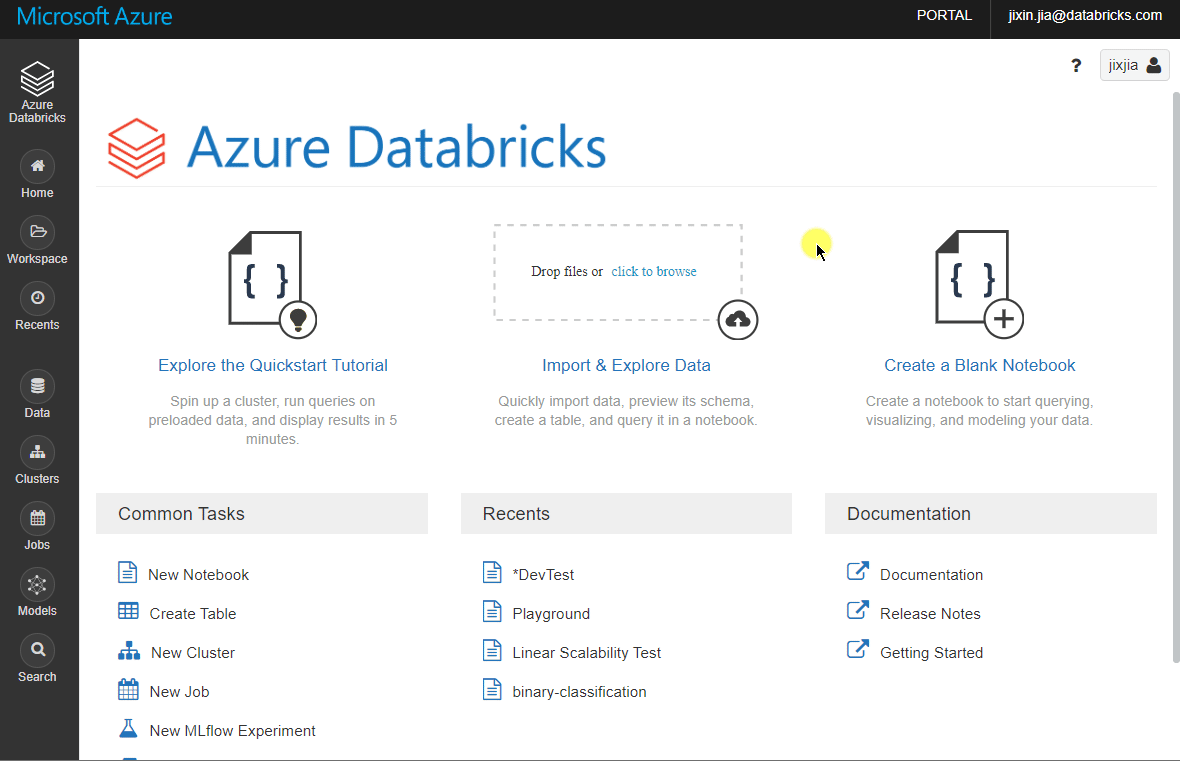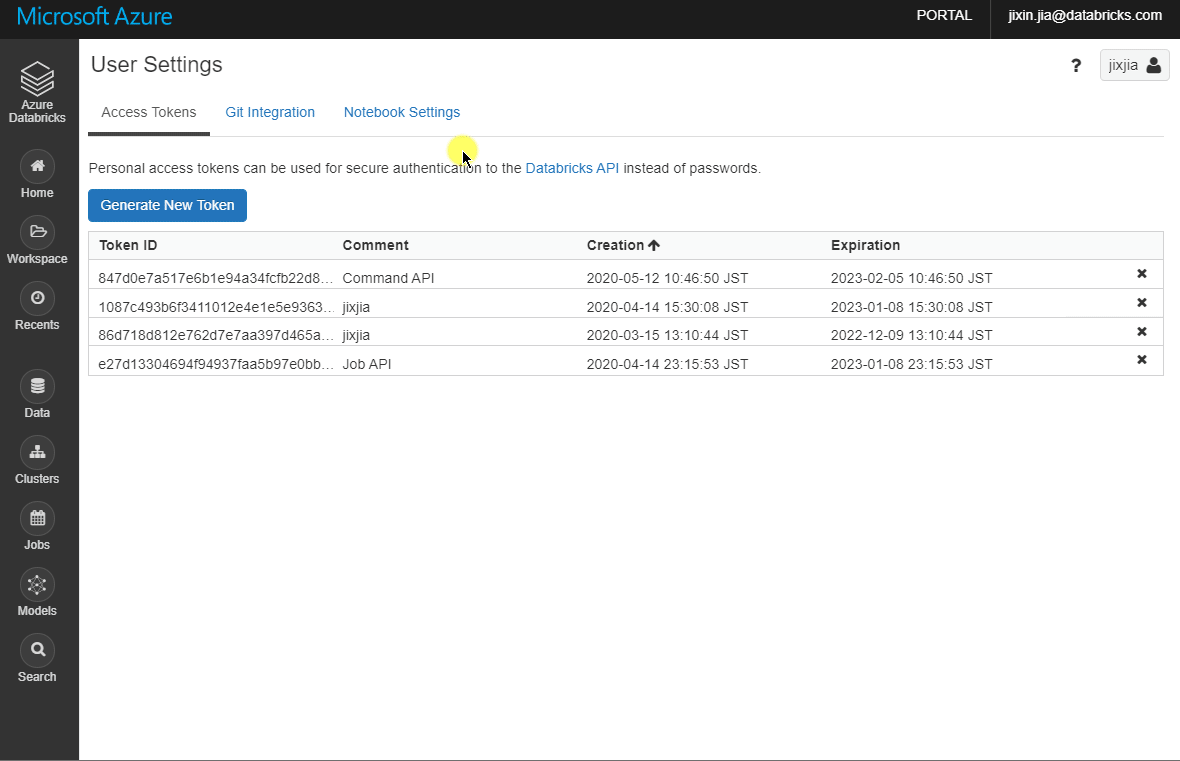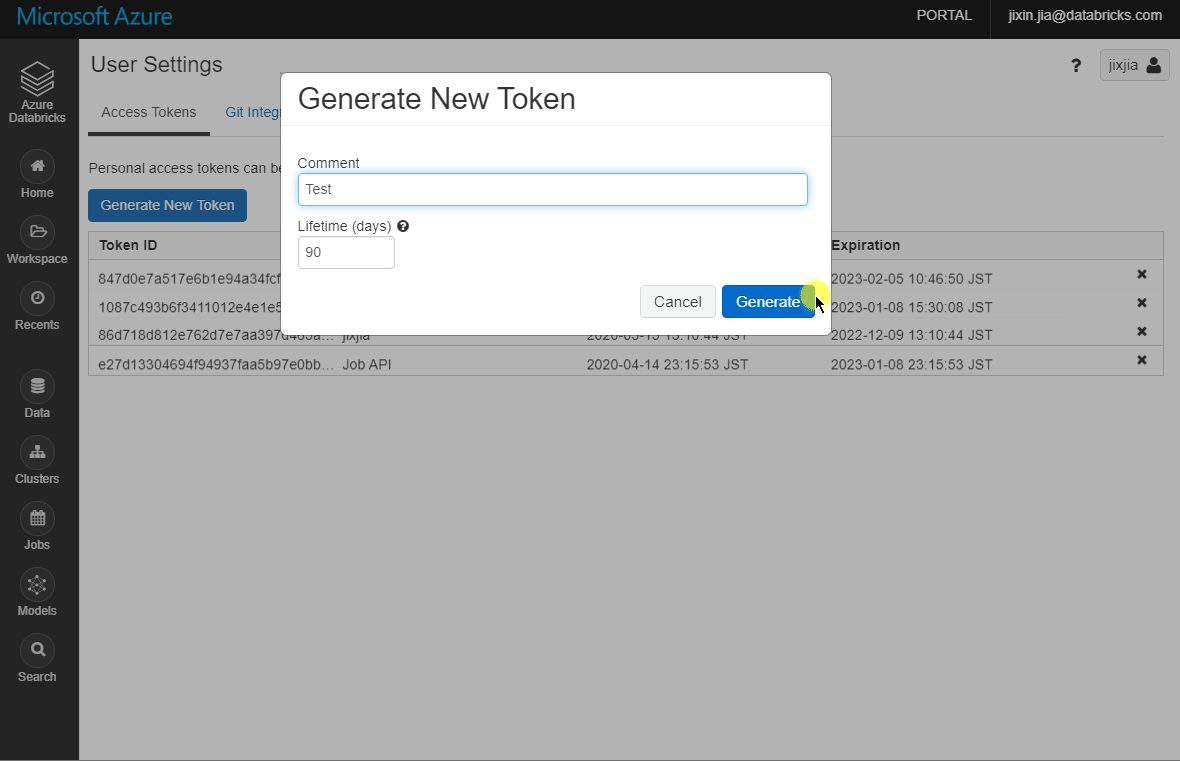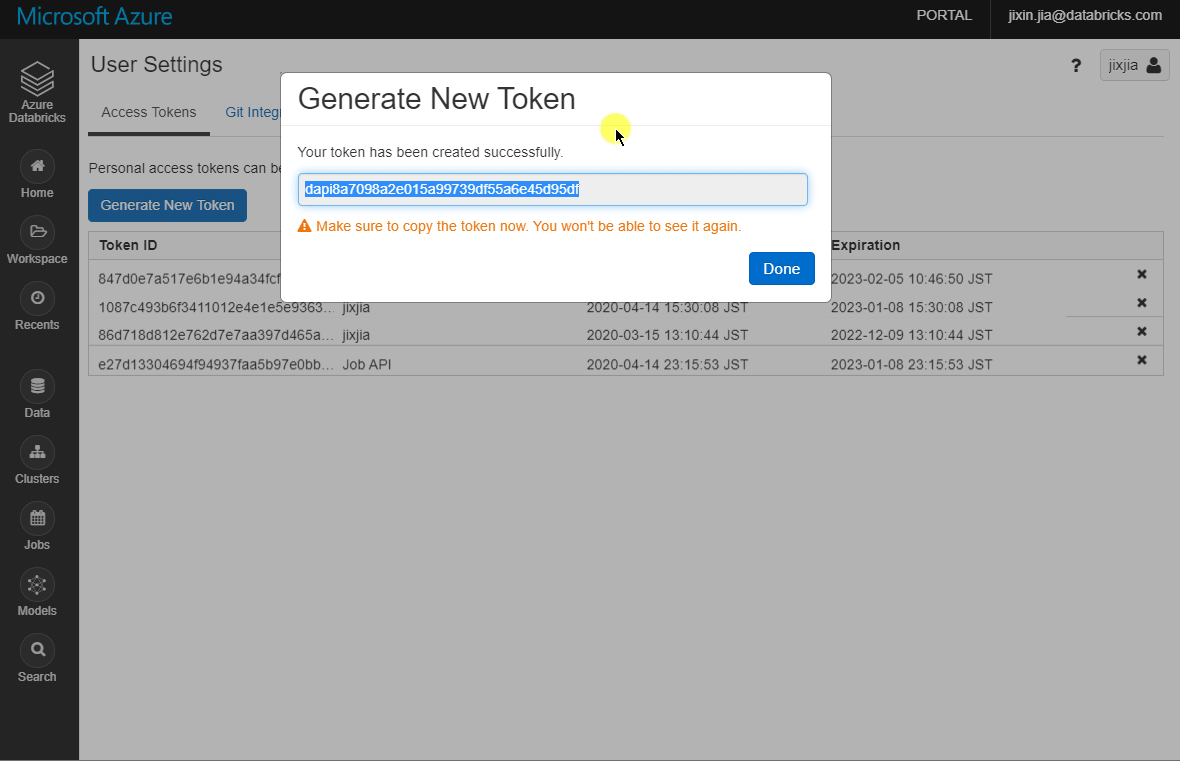
(2) Personal Access Token
Get this from your Databricks workspace by clicking Your Name > User Settings > Generate New Token. Take a note of this token as it won’t show up again after the window closes:
Known Limitations
This Command API is really handy when you wish to quickly execute a snippet of code or run a debugging session in your favorite IDE. It saves you from having to open your browser, find workspace, log in and then open up the Notebook (oh, not to forget to attach a cluster to it). However, the Command API belongs to the older version 1.2 REST API group and hasn’t been actively developed lately. For example, you are able to run a file containing your Spark code with this API, but you do have to upload the file to DBFS first using another API called DBFS PUT (which belongs to the version 2.0 API group) before Command API can execute the file. Also it doesn’t support Notebook Run Workflow (i.e. %run command) which means the API is not quite designed for scenarios that involve using multiple Notebooks for orchestrating a complex Databricks Job workflow.
With all that said, the Command API is arguably the most convenient way to run an ad-hoc query against Databricks, and is best suited for when you wish to execute a chunk of Spark query as part of your overall app workflow.
